
基本定义
在机器学习领域或者统计领域,用于衡量模型优劣的一种方法。首先要熟悉如下几个概念:
TP:真阳性,数据本身是阳性的,模型对该样本的评价也是阳性的,这是我们期待的。TN:真阴性,数据本身是阴性的,模型对该样本的评价也是阴性的,这也是我们期待的。FP:假阳性,数据本身是阴性的,模型对该样本的评价是阳性的,也不是我们期待的。FN:假阴性,数据本身是阳性的,模型对该样本的评价是阴性的,这不是我们期待的。
狼来了(精简版)
上面的这几个概念看起来比较绕,用一个实际的例子可以这么表达,假如有一个“狼来了”的模型,可以识别狼是否来了。那么套用上面的几个概念可以表达为
我们做出以下定义:
- “狼来了”是正类别。
- “没有狼”是负类别。
我们可以使用一个 2x2 混淆矩阵来总结我们的“狼预测”模型,该矩阵描述了所有可能出现的结果(共四种):
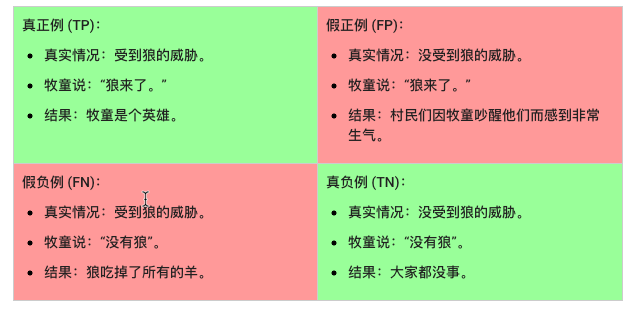
真正例是指模型将正类别样本正确地预测为正类别。同样,真负例是指模型将负类别样本正确地预测为负类别。
假正例是指模型将负类别样本错误地预测为正类别,而假负例是指模型将正类别样本错误地预测为负类别。
假正例,在混淆矩阵也叫做Type Error 1,假负例,在混淆矩阵中叫做Type Error 2。
TPR:在所有实际为阳性的样本中,被正确地判断为阳性的比例。
FPR:在所有实际为阴性的样本中,被错误地判断为阳性的比例1
2TPR = TP/(TP+FN)
FPR = FP/(FP+TN)
召回率
召回率(Recall Rate,也叫查全率)是检索出的相关文档数和文档库中所有的相关文档数的比率,衡量的是检索系统的查全率;精度是检索出的相关文档数与检索出的文档总数的比率,衡量的是检索系统的查准率。
也就是查全率,数值越大意味着覆盖的越全面。
公式为:1
R = TP/ (TP+FN)
例如在医疗系统中,尽量的覆盖更高的召回率,这样就减少漏掉病症的情况,虽然精准率收到影响,也就是说可能把没有病的当成有病的了(FP增多)。
精准率
正确预测为正占全部预测为正的比例,只能评估模型在样本数据中的准确率。
公式为:1
P = TP / (TP + FP)
拔河比赛
精准率和召回率本身是一场拔河比赛。
后续更新。